Any function in Python that contains the keyword yield is called a generator function.
When called, a generator function returns a generator object that “wraps” the body of the function.
When an object of the generator is passed to the next() function, execution continues until the next yield statement in the function body, and the value associated with that yield is returned.
When the function exits, the generator object raises a StopIteration exception according to the Iterator protocol.
Therefore, a generator function can be used wherever an iterator can be used, such as in loops.
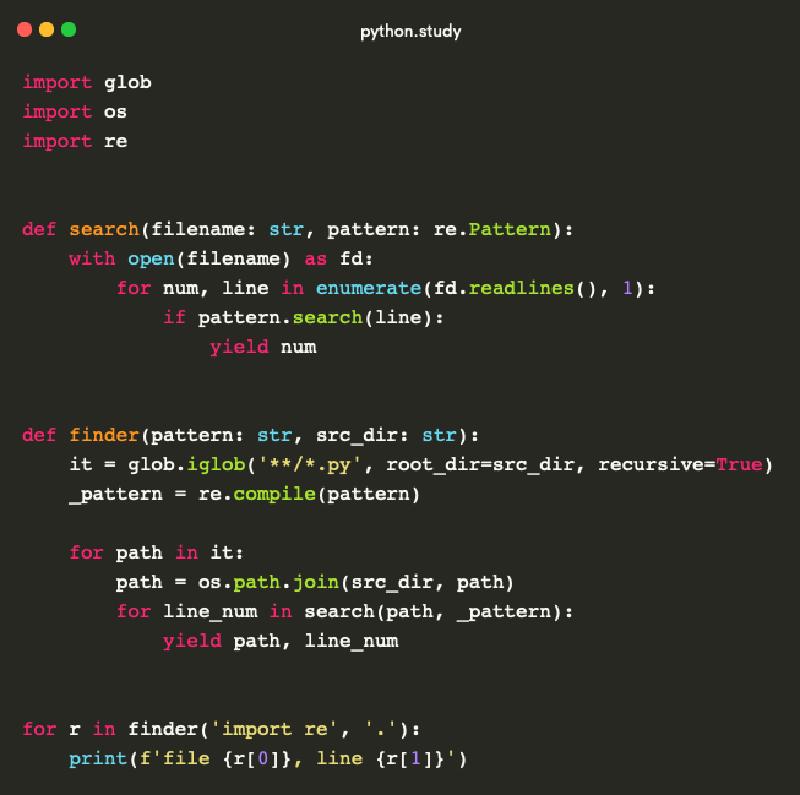
Let’s consider an example of a generator function called finder that searches for a specific string in Python source code files (files with the extension *.py).
The string can be represented by a regular expression.
In addition to the search string, our generator function will also take the path to the directory containing the code.
The example code for the finder generator function is shown below. Note that finder uses another generator function called search to determine the line number where a match was found.
import glob
import os
import re
def search(filename: str, pattern: re.Pattern):
with open(filename) as fd:
for num, line in enumerate(fd.readlines(), 1):
if pattern.search(line):
yield num # line number in the file where a match was found
def finder(pattern: str, src_dir: str):
it = glob.iglob('**/*.py', root_dir=src_dir, recursive=True)
_pattern = re.compile(pattern)
for path in it:
path = os.path.join(src_dir, path)
for line_num in search(path, _pattern):
yield path, line_num
gen_obj = finder('import re', '.')
print(next(gen_obj)) # ('./example.py', 3)
print(next(gen_obj)) # ('./example.py', 23)
# Generator is an iterator
from collections.abc import Iterator
print(isinstance(gen_obj, Iterator)) # True
# ...which means that a generator function can be used in a loop
for r in finder('import re', '.'):
print(f'file {r[0]}, line {r[1]}')
# Output in the loop:
# file ./example.py, line 3
# file ./example.py, line 23
# and so on...
In this example, we will explore some subtle aspects of using generator functions.
return
In the example, the return from the generator function happens implicitly (there is no explicit return statement).
The question arises: what if there is an explicit return statement that returns a value?
How can the calling code access this returned value?
It turns out that the returned value will be passed to the value field of the StopIteration exception!
Let’s modify our generator function code to return the total number of matches found and print it.
import glob
import os
import re
def search(filename: str, pattern: re.Pattern):
with open(filename) as fd:
for num, line in enumerate(fd.readlines(), 1):
if pattern.search(line):
yield num # line number in the file where a match was found
def finder(pattern: str, src_dir: str):
it = glob.iglob('**/*.py', root_dir=src_dir, recursive=True)
_pattern = re.compile(pattern)
total = 0
for path in it:
path = os.path.join(src_dir, path)
for line_num in search(path, _pattern):
yield path, line_num
total += 1
# explicit return statement in the function
return total # total number of matches found
gen_obj = finder('import re', '.')
try:
while True:
print(next(gen_obj))
except StopIteration as ctx:
# the returned value is stored in the value field of
# the StopIteration exception
print(ctx.value) # total number of matches found
Doing the same thing in a for loop is not possible because the StopIteration exception will be implicitly caught and handled.
In other words, we won’t have access to it.
In fact, an explicit return statement with a value is very rare in generator functions and is mostly used for debugging purposes.
yield from
Let’s pay attention to the yield statement in the code of the generator function finder - it is located inside a loop.
The call to the generator function search returns a generator object, which is essentially an iterator that we iterate over in this loop.
In our case, we need to get everything that this iterator yields.
To achieve this, we don’t need the loop at all; it is enough to use the yield from statement.
Let’s rewrite the code of the generator function finder by adding yield from and removing the explicit loop over the iterator.
import glob
import os
import re
from itertools import repeat
def search(filename: str, pattern: re.Pattern):
with open(filename) as fd:
for num, line in enumerate(fd.readlines(), 1):
if pattern.search(line):
yield num # line number in the file where a match was found
def finder(pattern: str, src_dir: str):
it = glob.iglob('**/*.py', root_dir=src_dir, recursive=True)
_pattern = re.compile(pattern)
for path in it:
path = os.path.join(src_dir, path)
yield from zip(repeat(path), search(path, _pattern))
gen_obj = finder('import re', '.')
print(next(gen_obj)) # ('./example.py', 3)
print(next(gen_obj)) # ('./example.py', 5)
The expression zip(repeat(path), search(path, _pattern)) may look cumbersome, but that’s because our generator yields a tuple value - the file path and the line number where a match was found.
While the search generator yields line numbers, the path remains the same.
We can easily get a sequence of identical paths using the repeat iterator from the itertools module.
The zip function is used to yield tuples of values.
With the help of the itertools module and functions like zip, Python allows us to write code in a functional style.
However, it is important to keep the code understandable for others. We could have shortened the finder generator function to just one line (🤯), but it would have been extremely difficult to understand. Here’s an example:
import glob
import os
import re
from itertools import repeat, chain
def search(filename: str, pattern: re.Pattern):
with open(filename) as fd:
for num, line in enumerate(fd.readlines(), 1):
if pattern.search(line):
yield num # line number in the file where a match was found
def finder(pattern: str, src_dir: str):
yield from chain.from_iterable(
zip(repeat(path), search(path, re.compile(pattern)))
for path in (
os.path.join(src_dir, path)
for path in glob.iglob('**/*.py', root_dir=src_dir, recursive=True)
)
) # better not to write like this!
gen_obj = finder('import re', '.')
print(next(gen_obj)) # ('./example.py', 3)
print(next(gen_obj)) # ('./example.py', 5)
decorator
Applying a decorator to a generator function gives an unexpected result. The decorator does not wrap the body of the generator function. The decorator is executed when the generator function is called, and at this stage, only the generator object is created. Therefore, for example, if we try to measure the execution time of a generator function, we will only get the time it takes to create the generator itself. The simple example below demonstrates this:
import time
def timeit(func):
def wrapper(*args, **kwargs):
t = time.perf_counter()
result = func(*args, **kwargs)
elapsed = time.perf_counter() - t
print(f'elapsed {elapsed:0.8f}s')
return result
return wrapper
@timeit
def simple_func():
time.sleep(1)
simple_func() # output something like "elapsed 1.00515067s"
@timeit
def gen_func():
time.sleep(1)
yield 1
list(gen_func()) # output something like "elapsed 0.00001092s"
In this example, the timeit decorator, which wraps the generator function gen_func, is not very useful.
However, it is possible to write a decorator for a generator function.
For example, we can rewrite timeit like this:
import time
def timeit(func):
def wrapper(*args, **kwargs):
t = time.perf_counter()
yield from func(*args, **kwargs)
elapsed = time.perf_counter() - t
print(f'elapsed {elapsed:0.8f}s')
return wrapper
@timeit
def gen_func():
time.sleep(1)
yield 1
time.sleep(1)
yield 2
list(gen_func()) # output something like "elapsed 2.00686138s"
async generator
A generator function can be asynchronous, in which case it will create asynchronous generators (async_generator).
To work with asynchronous generators in Python, there is the async for construct.
Let’s rewrite our generator function finder in an asynchronous form, using async for to work with the generator.
import asyncio
import glob
import os
import re
async def search(filename: str, pattern: re.Pattern):
with open(filename) as fd:
for num, line in enumerate(fd.readlines(), 1):
if pattern.search(line):
yield num # line number in the file where a match was found
async def finder(pattern: str, src_dir: str):
it = glob.iglob('**/*.py', root_dir=src_dir, recursive=True)
_pattern = re.compile(pattern)
for path in it:
path = os.path.join(src_dir, path)
async for line_num in search(path, _pattern):
yield path, line_num
async def main():
async for r in finder('import re', '.'):
print(f'file {r[0]}, line {r[1]}')
if __name__ == '__main__':
asyncio.run(main())
It was not difficult to rewrite the generator function as an asynchronous one.
coroutines
In PEP 342 “Coroutines via Enhanced Generators” it is stated that generators can be used as coroutines.
For this purpose, generators have special methods such as .send() and .throw(), and the yield statement not only yields values but also consumes them.
When you see such usage of a generator function, know that it is a coroutine.
And a coroutine is not an iterator!
Coroutines have nothing to do with iteration.
Moreover, with the advent of asyncio, the use of generators as coroutines becomes almost obsolete.
Nevertheless, it is important to be able to recognize a “classic” coroutine in the code to understand that it is not about iteration.
Let’s provide an example of such a coroutine:
def adder():
acc = 0
while True:
x = yield acc
acc += x
coro_add = adder()
next(coro_add)
print(coro_add.send(1)) # 1 (0 + 1)
print(coro_add.send(2)) # 3 (1 + 2)
print(coro_add.send(3)) # 6 (3 + 3)
print(coro_add.send(4)) # 10 (6 + 4)
Pay attention to the yield statement.
In this case, yield not only yields the value of acc but also accepts a value that is passed through the send method call.
Coroutines consume data, while iterators produce data.
Even though both cases use the yield keyword, they are two completely different uses of generator functions.
That’s all for now.
Additional information about generator functions and generators can be found in the following documents:
